OBJECT OF WONDER
11
AlphaGo · Game 2 ·
2016
︎︎︎ Play by Play
︎︎︎ Mechanical Turk
︎︎︎ Deep Blue vs. Garry Kasparov
︎︎︎ Financial Markets
11
AlphaGo · Game 2 ·
Move 37
2016
︎︎︎ Play by Play
︎︎︎ Mechanical Turk
︎︎︎ Deep Blue vs. Garry Kasparov
︎︎︎ Financial Markets
Developed by Google subsidiary, DeepMind, AlphaGo is a computer program that plays Go, a popular strategy game. AlphaGo versus Lee Sedol—a best out of five Go tournament held in Seoul, South Korea in March 2016—pitted Go master Lee against the computer program. AlphaGo employed several deep neural networks, which it trained by playing against itself and strengthened with reinforcement learning. In other words, AlphaGo learned more from its own experience than it did from the experts who programmed it.
Before the match, a confident Lee predicted that he would sweep all five games. “It is just a program,” he said, “lacking insight and creativity.” Lee was devastated by his loss to AlphaGo in Game 1.
However, what really confounded experts and Lee was the unorthodox Move 37 by AlphaGo in Game 2. The international Go masters who were providing commentary for the match thought that AlphaGo might have made an error. Even the AlphaGo team was surprised. As the game progressed, it became clear that Move 37 was a brilliant, even creative move that pivoted the game and set it off in a new direction. AlphaGo “knew” that it was an unusual move—it had calculated that there was less than a 1 in 10,000 chance that a human would have made the same move. AlphaGo went on to win Game 2, as well as Games 3 and 5.
Before the match, a confident Lee predicted that he would sweep all five games. “It is just a program,” he said, “lacking insight and creativity.” Lee was devastated by his loss to AlphaGo in Game 1.
However, what really confounded experts and Lee was the unorthodox Move 37 by AlphaGo in Game 2. The international Go masters who were providing commentary for the match thought that AlphaGo might have made an error. Even the AlphaGo team was surprised. As the game progressed, it became clear that Move 37 was a brilliant, even creative move that pivoted the game and set it off in a new direction. AlphaGo “knew” that it was an unusual move—it had calculated that there was less than a 1 in 10,000 chance that a human would have made the same move. AlphaGo went on to win Game 2, as well as Games 3 and 5.
︎
Text To Speech
Text To Speech
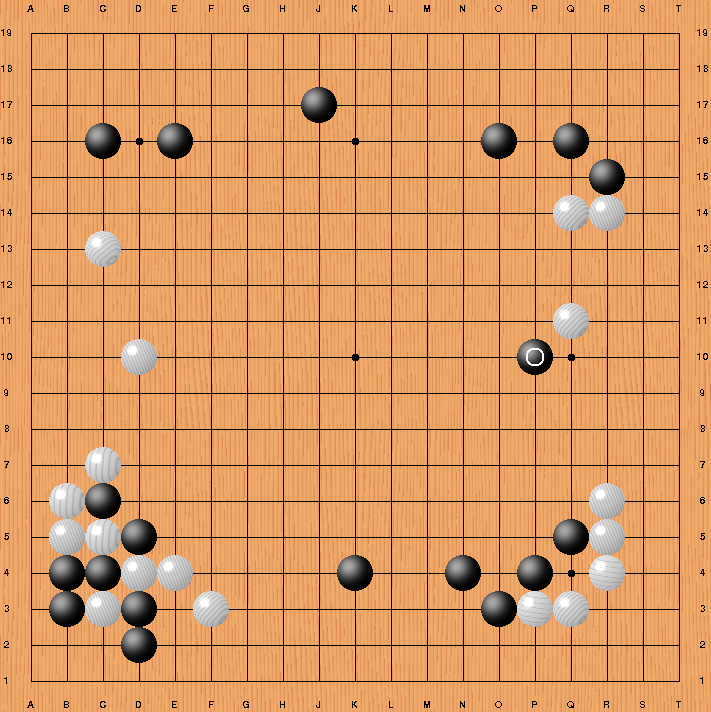
AlphaGo vs. Lee Sedol, Game 2, Move 37, 2016
